本文共 10210 字,大约阅读时间需要 34 分钟。
编程进阶— C语言(二)— 整型
整型
在C语言中,整型数据一般用short、int、long三种数据类型来声明,int是C语言中常用的声明整形数据的数据类型,在现代的操作系统中,一般是占4字节(Byte)即32位(Bit),4字节可以存储很大的数值,为了节省空间,避免造成不必要的浪费,对于较小的数据,可以用short int来声明,也可以省略int;对于太大的数据,可以用long int来声明,也可以省略int。
short、int、long 是C语言中常见的整数类型,其中 int 称为整型,short 称为短整型,long 称为长整型。
整型的长度
一种数据类型占用的字节数,称为该数据类型的长度。例如,short 占用 2 个字节的内存,那么它的长度就是 2。
实际情况也确实如此,C语言并没有严格规定 short、int、long 的长度,只做了宽泛的限制:- short 至少占用 2 个字节。
- int 建议为一个机器字长。32 位环境下机器字长为 4 字节,64 位环境下机器字长为 8 字节。
- short 的长度不能大于 int,long 的长度不能小于 int。
总结起来,它们的长度(所占字节数)关系为:
2 ≤ short ≤ int ≤ long这就意味着,short 并不一定真的”短“,long 也并不一定真的”长“,它们有可能和 int 占用相同的字节数。
在 16 位环境下,short 的长度为 2 个字节,int 也为 2 个字节,long 为 4 个字节。16 位环境多用于单片机和低级嵌入式系统,在PC和服务器上已经见不到了。
对于 32 位的 Windows、Linux 和 Mac OS,short 的长度为 2 个字节,int 为 4 个字节,long 也为 4 个字节。PC和服务器上的 32 位系统占有率也在慢慢下降,嵌入式系统使用 32 位越来越多。
在 64 位环境下,不同的操作系统会有不同的结果,如下所示:
| 操作系统 | short | int | long |
|---|---|---|---|
| Win64 | 2 | 4 | 4 |
| 类Unix系统(包括 Unix、Linux、Mac OS、BSD、Solaris 等) | 2 | 4 | 8 |
目前我们使用较多的PC系统为 Win XP、Win 7、Win 8、Win 10、Mac OS、Linux,在这些系统中,short 和 int 的长度都是固定的,分别为 2 和 4,大家可以放心使用,只有 long 的长度在 Win64 和类 Unix 系统下会有所不同,使用时要注意移植性。
sizeof
获取某个数据类型的长度可以使用 sizeof 操作符,如下所示:
#includeint main(){ short a = 10; int b = 100; int short_length = sizeof a; int int_length = sizeof(b); int long_length = sizeof(long); int char_length = sizeof(char); printf("short=%d, int=%d, long=%d, char=%d\n", short_length, int_length, long_length, char_length); return 0;}
在 32 位环境以及 Win64 环境下的运行结果为:
short=2, int=4, long=4, char=1 在 64 位 Linux 和 Mac OS 下的运行结果为:
short=2, int=4, long=8, char=1 sizeof 用来获取某个数据类型或变量所占用的字节数,如果后面跟的是变量名称,那么可以省略( ),如果跟的是数据类型,就必须带上( )。
需要注意的是,sizeof 是C语言中的操作符,不是函数,所以可以不带( ),后面会详细讲解。
二进制、八进制、十六进制
二进制
二进制由0和1组成,使用时必须以0b或者0B(不区分大小写),
//合法的二进制int a = 0b101; //换算成十进制为 5int b = -0b110010; //换算成十进制为 -50int c = 0B100001; //换算成十进制为 33//非法的二进制int m = 101010; //无前缀 0B,相当于十进制int n = 0B410; //4不是有效的二进制数字
八进制
八进制由 0~7 八个数字组成,使用时必须以0开头(注意是数字 0,不是字母 o)
//合法的八进制数int a = 015; //换算成十进制为 13int b = -0101; //换算成十进制为 -65int c = 0177777; //换算成十进制为 65535//非法的八进制int m = 256; //无前缀 0,相当于十进制int n = 03A2; //A不是有效的八进制数字
十六进制
十六进制由数字 0~9、字母 A~F 或 a~f(不区分大小写)组成,使用时必须以0x或0X(不区分大小写)开头
//合法的十六进制int a = 0X2A; //换算成十进制为 42int b = -0XA0; //换算成十进制为 -160int c = 0xffff; //换算成十进制为 65535//非法的十六进制int m = 5A; //没有前缀 0X,是一个无效数字int n = 0X3H; //H不是有效的十六进制数字
十进制
十进制由 0~9 十个数字组成,没有任何前缀,和我们平时的书写格式一样,不再赘述。
二进制数、八进制数和十六进制数的输出
C语言中常用的整数有 short、int 和 long 三种类型,通过 printf 函数,可以将它们以八进制、十进制和十六进制的形式输出。上节我们讲解了如何以十进制的形式输出,这节我们重点讲解如何以八进制和十六进制的形式输出,下表列出了不同类型的整数、以不同进制的形式输出时对应的格式控制符:
| short | int | long | |
|---|---|---|---|
| 八进制 | %ho | %o | %lo |
| 十进制 | %hd | %d | %ld |
| 十六进制 | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
十六进制数字的表示用到了英文字母,有大小写之分,要在格式控制符中体现出来:
- %hx、%x 和 %lx 中的x小写,表明以小写字母的形式输出十六进制数;
- %hX、%X 和 %lX 中的X大写,表明以大写字母的形式输出十六进制数。
实例
#includeint main(){ short a = 0b1010110; //二进制数字 int b = 02713; //八进制数字 long c = 0X1DAB83; //十六进制数字 printf("a=%ho, b=%o, c=%lo\n", a, b, c); //以八进制形似输出 printf("a=%hd, b=%d, c=%ld\n", a, b, c); //以十进制形式输出 printf("a=%hx, b=%x, c=%lx\n", a, b, c); //以十六进制形式输出(字母小写) printf("a=%hX, b=%X, c=%lX\n", a, b, c); //以十六进制形式输出(字母大写) return 0;}
结果
a=126, b=2713, c=7325603a=86, b=1483, c=1944451a=56, b=5cb, c=1dab83a=56, b=5CB, c=1DAB83
输出时加上前缀
注意观察上面的例子,会发现有一点不完美,如果只看输出结果:- 对于八进制数字,它没法和十进制、十六进制区分,因为八进制、十进制和十六进制都包含 0~7 这几个数字。
- 对于十进制数字,它没法和十六进制区分,因为十六进制也包含 0~9 这几个数字。如果十进制数字中还不包含 8 和 9,那么也不能和八进制区分了。
- 对于十六进制数字,如果没有包含 a~f 或者 A~F,那么就无法和十进制区分,如果还不包含 8 和 9,那么也不能和八进制区分了。
区分不同进制数字的一个简单办法就是,在输出时带上特定的前缀。在格式控制符中加上#即可输出前缀,例如 %#x、%#o、%#lX、%#ho 等,请看下面的代码:
#includeint main(){ short a = 0b1010110; //二进制数字 int b = 02713; //八进制数字 long c = 0X1DAB83; //十六进制数字 printf("a=%#ho, b=%#o, c=%#lo\n", a, b, c); //以八进制形似输出 printf("a=%hd, b=%d, c=%ld\n", a, b, c); //以十进制形式输出 printf("a=%#hx, b=%#x, c=%#lx\n", a, b, c); //以十六进制形式输出(字母小写) printf("a=%#hX, b=%#X, c=%#lX\n", a, b, c); //以十六进制形式输出(字母大写) return 0;}
运行结果:
a=0126, b=02713, c=07325603a=86, b=1483, c=1944451a=0x56, b=0x5cb, c=0x1dab83a=0X56, b=0X5CB, c=0X1DAB83
十进制数字没有前缀,所以不用加#。如果你加上了,那么它的行为是未定义的,有的编译器支持十进制加#,只不过输出结果和没有加#一样,有的编译器不支持加#,可能会报错,也可能会导致奇怪的输出;但是,大部分编译器都能正常输出,不至于当成一种错误。
正负数及输出
short、int、long型都可以表示整数和负数,如果不带符号,那么表示默认是正数;
//负数short a1 = -10;short a2 = -0x2dc9; //十六进制//正数int b1 = +10;int b2 = +0174; //八进制int b3 = 22910;//负数和正数相加long c = (-9) + (+12);
在内存中,用1位来表示符号位,C语言规定,把内存的最高位作为符号位,用 0 表示正数,用 1 表示负数。以int型为例,它占用32位的内存,bit0~30表示数值,bit31表示符号位。
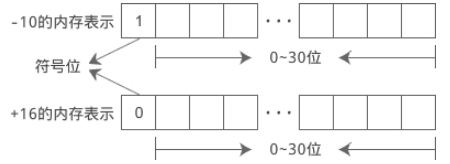 short、int 和 long 类型默认都是带符号位的,符号位以外的内存才是数值位。如果只考虑正数,那么各种类型能表示的数值范围(取值范围)就比原来小了一半。
short、int 和 long 类型默认都是带符号位的,符号位以外的内存才是数值位。如果只考虑正数,那么各种类型能表示的数值范围(取值范围)就比原来小了一半。 C语言允许我们不设置符号位,在数据类型的前面加上unsigned关键字,这种称为无符号数。
unsigned short a = 12;unsigned int b = 1002;unsigned long c = 9892320;
这种写法表示,short、int、long没有符号位,所有的位都用来表示数值,正数的取值范围就更大了,但也不能再表示负数。
无符号数的输出
| unsigned short | unsigned int | unsigned long | |
|---|---|---|---|
| 八进制 | %ho | %o | %lo |
| 十进制 | %hu | %u | %lu |
| 十六进制 | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
如何以八进制和十六进制形式输出有符号数呢?很遗憾,printf 并不支持,也没有对应的格式控制符。在实际的开发过程中也不会有输出八进制或者十六进制负数的需求。
下表全面地总结了不同类型的整数,以不同进制的形式输出时对应的格式控制符(–表示没有对应的格式控制符)。
| short | int | long | unsigned short | unsigned int | unsigned long | |
|---|---|---|---|---|---|---|
| 八进制 | - | - | - | %ho | %o | %lo |
| 十进制 | %hd | %d | %ld | %hu | %u | %lu |
| 十六进制 | - | - | - | %hx 或者 %hX | %x 或者 %X | %lx 或者 %lX |
printf
在使用printf函数输出,它不会管变量定义时是有符号数还是无符号数,而是从内存中取出变量,按照给定的控制格式符来输出。这是因为:
- 对于printf 1. 当以有符号数的形式输出时,printf 会读取数字所占用的内存,并把最高位作为符号位,把剩下的内存作为数值位; 2. 当以无符号数的形式输出时,printf 也会读取数字所占用的内存,并把所有的内存都作为数值位对待。
- 对于控制格式符 1. 你让我输出无符号数,那我在读取内存时就不区分符号位和数值位了,我会把所有的内存都看做数值位; 2. 你让我输出有符号数,那我在读取内存时会把最高位作为符号位,把剩下的内存作为数值位。
#includeint main(){ short a = 0100; //八进制 int b = -0x1; //十六进制 long c = 720; //十进制 unsigned short m = 0xffff; //十六进制 unsigned int n = 0x80000000; //十六进制 unsigned long p = 100; //十进制 //以无符号的形式输出有符号数 printf("a=%#ho, b=%#x, c=%ld\n", a, b, c); //以有符号数的形式输出无符号类型(只能以十进制形式输出) printf("m=%hd, n=%d, p=%ld\n", m, n, p); return 0;}
结果
a=0100, b=0xffffffff, c=720 //无符号形式输出有符号数m=-1, n=-2147483648, p=100 //有符号形式输出无符号数
从内存的角度看b、m、n的输出
 当以 %x 输出 b 时,结果应该是 0x80000001;当以 %hd、%d 输出 m、n 时,结果应该分别是 -7fff、-0。但是实际的输出结果和我们推理的结果却大相径庭,这是为什么呢?这跟整数在内存中的存储形式以及读取方式有关。b 是一个有符号的负数,它在内存中并不是像上图演示的那样存储,而是要经过一定的转换才能写入内存;m、n 的内存虽然没有错误,但是当以 %d 输出时,并不是原样输出,而是有一个逆向的转换过程(和存储时的转换过程恰好相反)。
当以 %x 输出 b 时,结果应该是 0x80000001;当以 %hd、%d 输出 m、n 时,结果应该分别是 -7fff、-0。但是实际的输出结果和我们推理的结果却大相径庭,这是为什么呢?这跟整数在内存中的存储形式以及读取方式有关。b 是一个有符号的负数,它在内存中并不是像上图演示的那样存储,而是要经过一定的转换才能写入内存;m、n 的内存虽然没有错误,但是当以 %d 输出时,并不是原样输出,而是有一个逆向的转换过程(和存储时的转换过程恰好相反)。 整数在内存中的存储形式以及读取方式
在计算机中,为了同时实现加法和减法的运算,简化电路,在对有符号数的存储和读取时,都要进行转换。
原码
将一个整数转换成二进制形式,就是其原码。
反码
- 正数的反码,就是原码;
- 负数的反码,就是将其原码除符号位以外,全部取反。
补码
- 正数的补码,就是原码;
- 负数的补码,反码加一。
short a =6; //a的原码0000 0000 0000 0110,a的反码0000 0000 0000 0110,a的补码0000 0000 0000 0110short b = -18; //b的原码1000 0000 0001 0010,b的反码1111 1111 1110 1101,b的补码1111 1111 1110 1110

6 - 18 = 6 + (-18)= [0000 0000 0000 0110]补 + [1111 1111 1110 1110]补= [1111 1111 1111 0100]补= [1111 1111 1111 0011]反= [1000 0000 0000 1100]原= -1218 - 6 = 18 + (-6)= [0000 0000 0001 0010]补 + [1111 1111 1111 1010]补= [1 0000 0000 0000 1100]补= [0000 0000 0000 1100]补= [0000 0000 0000 1100]反= [0000 0000 0000 1100]原= 125 - 13 = 5 + (-13)= [0000 0000 0000 0101]补 + [1111 1111 1111 0011]补= [1111 1111 1111 1000]补= [1111 1111 1111 0111]反= [1000 0000 0000 1000]原= -813 - 5 = 13 + (-5)= [0000 0000 0000 1101]补 + [1111 1111 1111 1011]补= [1 0000 0000 0000 1000]补 = [0000 0000 0000 1000]补= [0000 0000 0000 1000]反= [0000 0000 0000 1000]原= 8
上一小节使用printf输出数据时,结果会出现异常,这边就可以解释了
#includeint main(){ short a = 0100; //八进制 int b = -0x1; //十六进制 long c = 720; //十进制 unsigned short m = 0xffff; //十六进制 unsigned int n = 0x80000000; //十六进制 unsigned long p = 100; //十进制 //以无符号的形式输出有符号数 printf("a=%#ho, b=%#x, c=%ld\n", a, b, c); //以有符号数的形式输出无符号类型(只能以十进制形式输出) printf("m=%hd, n=%d, p=%ld\n", m, n, p); return 0;}
结果
a=0100, b=0xffffffff, c=720 //无符号形式输出有符号数m=-1, n=-2147483648, p=100 //有符号形式输出无符号数
其中,b、m、n 的输出结果看起来非常奇怪。
b 是有符号数,它在内存中的存储形式(也就是补码)为:
b = -0x1= [1000 0000 …… 0000 0001]原= [1111 1111 …… 1111 1110]反= [1111 1111 …… 1111 1111]补= [0xffffffff]补
%#x表示以无符号的形式输出,而无符号数的补码和原码相同,所以不用转换了,直接输出 0xffffffff 即可。
m 和 n 是无符号数,它们在内存中的存储形式为:
m = 0xffff= [1111 1111 1111 1111]补n = 0x80000000= [1000 0000 …… 0000 0000]补
%hd和**%d**表示以有符号的形式输出,所以还要经过一个逆向的转换过程:
[1111 1111 1111 1111]补= [1111 1111 1111 1110]反= [1000 0000 0000 0001]原= -1[1000 0000 …… 0000 0000]补= -231= -2147483648
由此可见,-1 和 -2147483648 才是最终的输出值。
注意,[1000 0000 …… 0000 0000]补是一个特殊的补码,无法按照本节讲到的方法转换为原码,所以计算机直接规定这个补码对应的值就是 -2^31,至于为什么,下节我们会详细分析。整数的取值范围以及数值溢出
- 无符号数(unsigned 类型)的取值范围,将内存中的所有位(Bit)都置为 1 就是最大值,都置为 0 就是最小值。
- 有符号数以补码的形式存储,计算取值范围也要从补码入手,以char型为例:
 淡黄色背景的那一行是我要重点说明的。如果按照传统的由补码计算原码的方法,那么 1000 0000 是无法计算的,因为计算反码时要减去 1,1000 0000 需要向高位借位,而高位是符号位,不能借出去,所以这就很矛盾。
淡黄色背景的那一行是我要重点说明的。如果按照传统的由补码计算原码的方法,那么 1000 0000 是无法计算的,因为计算反码时要减去 1,1000 0000 需要向高位借位,而高位是符号位,不能借出去,所以这就很矛盾。
是不是该把 1000 0000 作为无效的补码直接丢弃呢?然而,作为无效值就不如作为特殊值,这样还能多存储一个数字。计算机规定,1000 0000 这个特殊的补码就表示 -128。
为什么偏偏是 -128 而不是其它的数字呢?
首先,-128 使得 char 类型的取值范围保持连贯,中间没有“空隙”。
其次,我们再按照“传统”的方法计算一下 -128 的补码:
- -128 的数值位的原码是 1000 0000,共八位,而 char 的数值位只有七位,所以最高位的 1 会覆盖符号位,数值位剩下 000 0000。最终,-128 的原码为 1000 0000。
- 接着很容易计算出反码,为 1111 1111。
- 反码转换为补码时,数值位要加上 1,变为 1000 0000,而 char 的数值位只有七位,所以最高位的 1 会再次覆盖符号位,数值位剩下 000 0000。最终求得的 -128 的补码是 1000 0000。
-128 从原码转换到补码的过程中,符号位被 1 覆盖了两次,而负数的符号位本来就是 1,被 1 覆盖多少次也不会影响到数字的符号。
你看,虽然从 1000 0000 这个补码推算不出 -128,但是从 -128 却能推算出 1000 0000 这个补码,这么多么的奇妙,-128 这个特殊值选得恰到好处。
负数在存储之前要先转换为补码,“从 -128 推算出补码 1000 0000”这一点非常重要,这意味着 -128 能够正确地转换为补码,或者说能够正确的存储。
关于零值和最小值 仔细观察上表可以发现,在 char 的取值范围内只有一个零值,没有+0和-0的区别,并且多存储了一个特殊值,就是 -128,这也是采用补码的另外两个小小的优势。如果直接采用原码存储,那么0000 0000和1000 0000将分别表示+0和-0,这样在取值范围内就存在两个相同的值,多此一举。另外,虽然最大值没有变,仍然是 127,但是最小值却变了,只能存储到 -127,不能存储 -128 了,因为 -128 的原码为 1000 0000,这个位置已经被-0占用了。
总结

数值溢出
char、short、int、long 的长度是有限的,当数值过大或者过小时,有限的几个字节就不能表示了,就会发生溢出。发生溢出时,输出结果往往会变得奇怪,请看下面的代码:
#includeint main(){ unsigned int a = 0x100000000; int b = 0xffffffff; printf("a=%u, b=%d\n", a, b); return 0;}运行结果:a=0, b=-1
变量 a 为 unsigned int 类型,长度为 4 个字节,能表示的最大值为 0xFFFFFFFF,而 0x100000000 = 0xFFFFFFFF + 1,占用33位,已超出 a 所能表示的最大值,所以发生了溢出,导致最高位的 1 被截去,剩下的 32 位都是0。也就是说,a 被存储到内存后就变成了 0,printf 从内存中读取到的也是 0。
变量 b 是 int 类型的有符号数,在内存中以补码的形式存储。0xffffffff 的数值位的原码为 1111 1111 …… 1111 1111,共 32 位,而 int 类型的数值位只有 31 位,所以最高位的 1 会覆盖符号位,数值位只留下 31 个 1,所以 b 的原码为:
1111 1111 …… 1111 1111 这也是 b 在内存中的存储形式。
当 printf 读取到 b 时,由于最高位是 1,所以会被判定为负数,要从补码转换为原码:
[1111 1111 …… 1111 1111]补= [1111 1111 …… 1111 1110]反= [1000 0000 …… 0000 0001]原= -1
最终 b 的输出结果为 -1。
转载地址:http://ajvzi.baihongyu.com/